
| L(OL)+ | (HO)+ | K(EK)*E | (HAR)+)+ |
| H(EH)+ | ROT?FL | TE(HE+)+ | LAW*L |
| MWA(HA)+ | HE(HE)+ | LO+L | HAHA* |
| (AH)+A+ | HA+ | (JA)+ | LULZ |
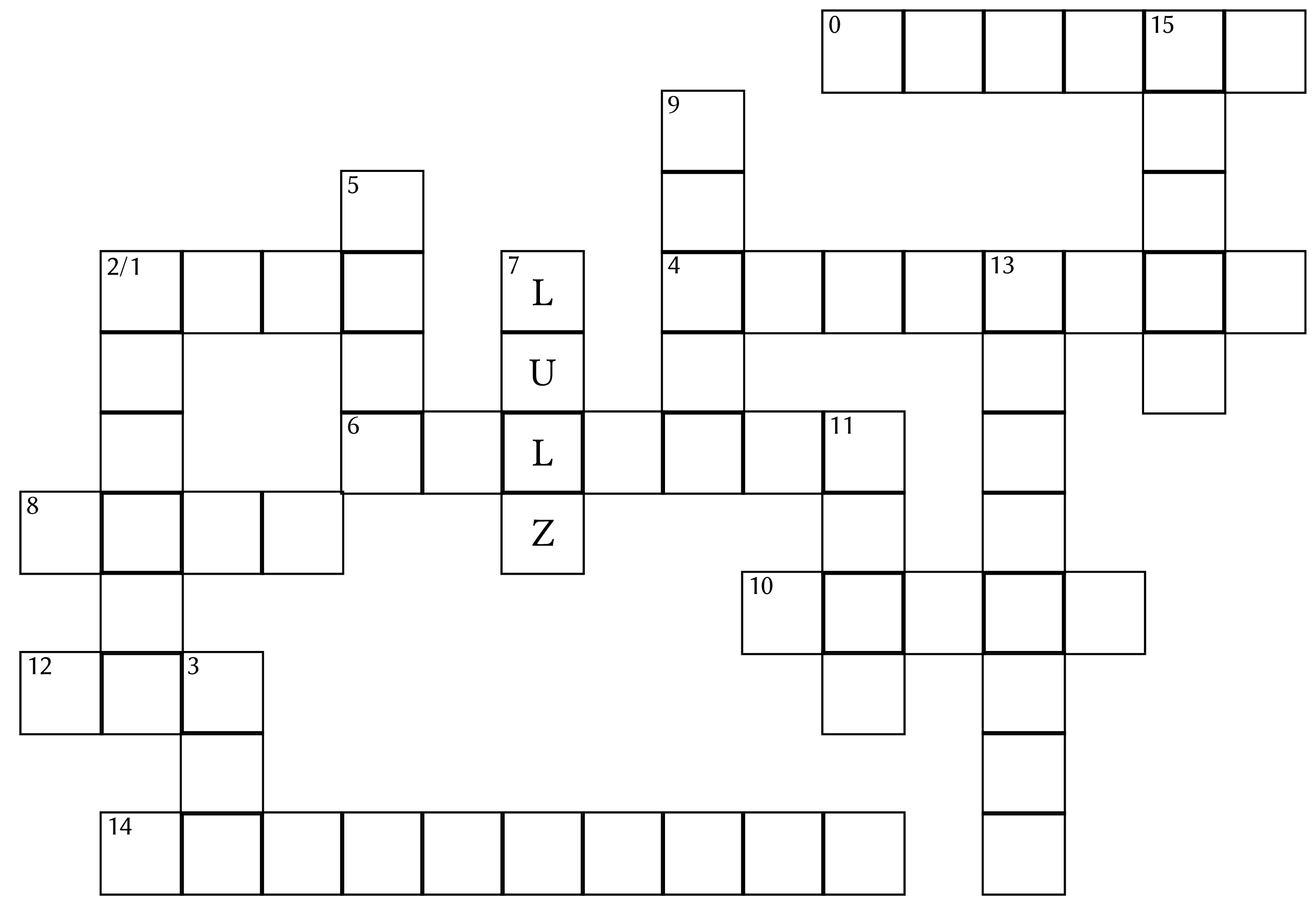
In this assignment you will write a program to solve crosswords, like the crossword above, created by Alex Bellos [1]. But the crossword entries, given in the table, look strange. Indeed, our crosswords will be different from traditional crosswords in the entry definitions: they will be given with regular expressions, or regexes.
Regular Expressions
Regular expressions are sequences of characters that describe strings. We use regular expressions when we want to describe a string following a pattern, instead of a particular string.
For example, if somebody asks you to locate a certain phone number in a file, you will try to match the given phone number with the contents of the file. But what if somebody asks to to find all phone numbers in a file? Similarly, if somebody asks you to find a particular e-mail address inside a file, you can simply search for it in the file. But what if you need to find all e-mail addresses that are present in the file? Or, you may want to find a word, taking into account different variants of it (or mispellings); say you want to find "neighbor" and "neighbour".
With regular expressions we use characters taken from the alphabet and some other, special characters, in order to describe the strings that we looking for. So:
-
The special character
*means that the preceding item may appear zero or more times. The regular expressionca*tdescribes the stringsct,cat,caat, etc. -
The special character
+means that the preceding item may appear one or more times. The regular expressionca+tdescribes the stringscat,caat,caaat, etc. -
The special character
?means that the preceding item may appear zero or one time. The regular expressionca?tdescribes the stringsctandcat.
An item can be a single character, as in our examples, or a group of
characters enclosed in brackets. The regular expression (ba)+boom
describes the strings baboom, bababoom, babababoom, etc.
Knowing regular expressions, you can solve the crossword at the beginning of this assignment, expanding the regular expressions given under the crossword as needed to cover all squares.
Solution Method
To solve the crossword, we must use an algorithm that tries all possible regular expressions until all squares are filled. We cannot do that in random, as it is infeasible to try all possible strings that are produced by the regular expressions given. We must adopt a somewhat more systematic approach, like the one below.
- While there are still entries that have not been filled:
- Pick an entry that has not been filled.
- Find the regular expressions that can fill the squares of the selected entry.
- For each one of these candidate regular expressions, fill the squares of the selected entry and continue recursively from step 1.
Requirements
You will write a program called re_crossword.py. You may use the
libraries: string,
re,
sre_yield,
csv,
argparse or
sys (in particular,
the list sys.argv) to handle program arguments.
To solve the crossword you must start with the regular expressions
that you can use to generate the strings that will fill the entries.
To generate the strings you will use the sre_yield library. This
library provides the function sre_yield.AllStrings(pattern) that
generates all the strings that correspond to the regular expression
pattern.
Your program will be called as follows:
python re_crossword.py crossword_file regular_expressions_file
The meaning of the program arguments is:
-
crossword_file: the file that contains the crossword description. -
regular_expressions_file: the file that contains the regular expressions that you will use on the crossword.
The format of crossword_file will be CSV (Comma Separated Values).
Each line will contain the following fields, which will be separated
by commas:
-
Crossword entry.
-
String representing the entry concents. Every unknown character is represented with a period (
.). -
One or more number pairs. The first number in a pair corresponds to the entry intersecting the current entry. The second number in each pair corresponds to the position of the intersecting character in the intersecting entry.
For example, the first line of laughs.csv
describes entry 0 of the crossword:
0,......,15,0
The entry has six unknown characters (......) and intersects entry 15
at position 0.
The last but one line of the same file describes entry 13 of the crossword:
13,........,4,4,10,3
The entry has eight unknown characters (........) and intersects
entry 4 at position 4 and entry 10 at position 3.
The entries will be numbered sequentially. Horizontal entries will be even-numbered and vertical entries will be odd-numbered, as you can see in the crossword at the start. If a square is the initial character of two entries, in the displayed crossword the square will be labelled with both of them, as happens with the square labelled 2/1.
The program output will be a sequence of lines of the form:
X regex word
where Χ is the number of the entry, regex is the regular
expression that fits, and word is the result of expanding the
regular expression so that the entry is filled. The output lines will
be sorted in ascending order by the entry number.
Implementation Notes
-
In step 2 of the algorithm that you will develop you must choose an entry that has not been filled yet. Choosing the right entry can have a very large impact on the number of steps that will be carried out and the overall speed of your program. A sensible strategy is to choose the entry with the greatest ratio of known letters over the entry lenght.
-
The function
sre_yield.AllStrings(pattern)can, depending on the regular expression, return a very large number of strings. To keep this number in check we can use the parametermax_count. For the purposes of this assignment,max_count=5, that is,sre_yield.AllStrings(pattern, max_count=5), should be enough. -
If the regular expression contains the special character
., then thesre_yield.AllStrings(pattern)functions will try all possible characters at that position. In our crosswords, however, we will only use upper case latin characters. To avoid trying characters that will never occur in the crossword, you should use the parametercharset, givingcharset=string.ascii_uppercase. Together with the previous point, the call should besre_yield.AllStrings(pattern, max_count=5, charset=string.ascii_uppercase). -
The
sre_yield.AllStrings(pattern)function may return the same string more than once, so you must ensure that you use each string once only.
Examples
Example 1
If you invoke the program with:
python re_crossword.py laughs.csv laughs.txt
then the program will read the file
laughs.csv,
which describes the crossword at the start of this assignment, and the
file
laughs.txt,
which describes the regular expressions. It will display the following
results:
0 HAHA* HAHAAA
1 HE(HE)+ HEHEHE
2 (HO)+ HOHO
3 HA+ HAA
4 TE(HE+)+ TEHEHEHE
5 LO+L LOOL
6 L(OL)+ LOLOLOL
7 LULZ LULZ
8 K(EK)*E KEKE
9 ROT?FL ROTFL
10 MWA(HA)+ MWAHA
11 LAW*L LAWL
12 H(EH)+ HEH
13 (HAR+)+ HARRHARR
14 (JA)+ JAJAJAJAJA
15 (AH)+A+ AHAHA
Example 2

If you invoke the program with:
python re_crossword.py films.csv films.txt
then the program will read the file
films.csv,
which describes the crossword, and the file
films.txt,
which describes the regular expressions, and will show the following output:
0 (M?ON)+CLE MONONCLE
1 SIDEWAYS SIDEWAYS
2 (((OU)|(GE))T)+ GETOUT
3 MO+D([FL]O[RV])+E MOODFORLOVE
4 (MAD?)+X MADMAX
5 ([BM]A[NT])+ BATMAN
6 S([TW]AR)+S STARWARS
7 SH(IN)+G SHINING
8 ([BL](AN?D))+S BADLANDS
9 S((EN)|(EV))+ SEVEN
10 S((EN)|(EV))+THSEAL SEVENTHSEAL
11 CA((S|BL|NC)A)+ CASABLANCA
12 ([CG]A[LR]I)+ CALIGARI
13 ([KB](ILL))+ KILLBILL
14 (SHA[WN])+K SHAWSHANK
15 (K[IO]NG)+ KINGKONG
16 (S?TOR?Y)+ TOYSTORY
Example 3
Our crosswords may be a bit unconventional, if we allow each entry position to intersect with two others, so instead of squares we will have hexagons, as in the following:
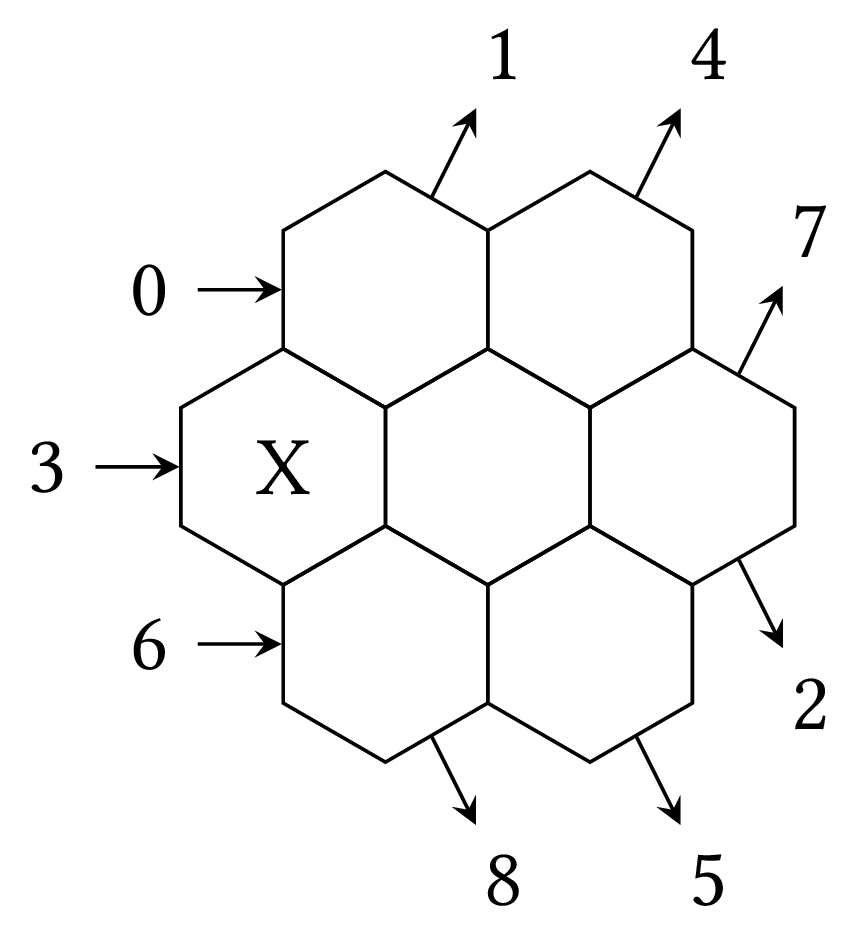
In this crossword we do not have only across and down entries, we have a dimension $x$, whose values are the numbers whose modulo with 3 is 0, a dimension $y$, whose values are the numbers whose modulo with 3 is 1, and a dimension $z$, whose modulo with 3 is 2. If that seems strange to you, note that this is the same rule we used previously, where the entries were numbered modulo 2.
If you invoke the program with:
python re_crossword.py hex.csv hex.txt
then the program will read the crossword description file
hex.csv
and the regular expressions file
hex.txt
and should produce the following output:
0 HE|HA|OH HE
1 NP|HX|SP HX
2 FN|EG|GN EG
3 .?[SAX][GAS].? XAG
4 .?[FAT][HOT].? EAO
5 .?[AND][NOT].? HAN
6 NO|ON|AT ON
7 XO|GN|PO GN
8 RO|GN|XO XO
Notes
It is possible that more than one solution exists for a given crossword; if your program produces a different answer than the ones above but still fills all the entries, it is of course correct.
Regular expressions were introduced in the 1950s by the American mathematician Stephen Cole Kleene [3]. Their widespread adoption in Computer Science began in 1968 when they were used for searching in a text editor [4] and lexical analysis in a compiler [2]. Regular expressions then became part of many tools available in the Unix operating system.
Regexes are a staple of data processing; there is plenty of material available online to learn how to use them and the Wikipedia Regular expression article is a good place to start. It is extremely unlikely that you will not benefit from getting acquainted with them, even if you only have to process data sporadically.
Bibliography
- Alex Bellos. The Language Lover's PuzzleBook: Lexical Perplexities and Cracking Conundrums from Across the Globe. Guardian Faber Publishing, 2020. ↩
- Walter L. Johnson, James H. Porter, Stephanie I. Ackley, and Douglas T. Ross. Automatic generation of efficient lexical processors using finite state techniques. Communications of the ACM, 11(12):805–813, December 1968. URL: https://doi.org/10.1145/364175.364185, doi:10.1145/364175.364185. ↩
- S. C. Kleene. Representation of events in nerve nets and finite automata. U.S. Air Force Project RAND Research Memorandum RM-704, The RAND Corporation, Santa Monica, CA, 1951. ↩
- Ken Thompson. Programming techniques: regular expression search algorithm. Communications of the ACM, 11(6):419–422, June 1968. URL: https://doi.org/10.1145/363347.363387, doi:10.1145/363347.363387. ↩